Why it is worth learning Golang

There are many references on how to do a simple Hello World in Go, but I would like to talk about other aspects with you. Let’s bring to the table the current stage of the hardware-software context and why a new language like Go is needed.
The origin of Go
There is some hearsay that GoLang’s idea occurred during the quiet period when one waits for a program with thousands and thousands lines to compile. They were tired of waiting and wasting their time. Three Google engineers have faced that situation many times before and decided to do something about it.
Rumors asaid, at a time that none of the existing languages were considering multi-threading as a main requirement, those three engineers, Robert Griesemer, Ken Thompson and Rob Pike, created a language whose compiler had efficient build times and that supported multi-threading as a primary requirement — in Go, concurrent programming constructions are embedded in the language itself. Go was announced in 2009, and the version 1.0 was released in 2012.
It is interesting to mention that Go creators have worked on some very important and significant projects in the past. This includes the creation of C, Unix, UTF-8, JVM and a few other programming languages and operating systems, such as the less known distributed OS Inferno .
Anyway, we have many languages in which we have efficient compilation, efficient execution or easy programming. Go is an attempt to bring all those facets into a single language.
Contextualizing hardware limitations
In mid-1965, Gordon E. Moore made his prophecy on the evolution of hardware: transistors would increase by 100%, at the same cost, every two years. This prophecy came true and eventually earned the name Moore’s Law. The principle has driven semiconductor development for decades. But now, innovation companies in US that once dominated the chip market has declined, investment capital has shrunk and production costs have risen. Nvidia CEO Jen-Hsun Huang not long ago stated that Moore’s Law is dead, and a 2016 MIT Technology Review article reached the same conclusion. Let’s look at some numbers:

In the chart above, we can see that single-thread performance and processor frequency have remained slightly stable for almost a decade. This is because, on a smaller scale, some quantum properties start to emerge (like tunneling) and because it actually costs more to put more transistors and the number of transistors you can add per dollar starts to fall. Furthermore, we can still cite the problem of the rise in operating temperature when this density increases.
Let’s see the updated data:

As you can see, transistor density has been increasing at a fairly stable exponential rate, even into 2018. The red line on this chart is transistor density, which isn’t really Moore’s Law. From 1971 to 2018 it grew at a compound annual growth rate (CAGR) of 32.12%. Instead of growing 2-fold every two years, it’s growing 1.746-fold every two years.
Without further ado, the big catch is that there always been a direct association of law with performance, but the law is much more than that.
So I think it is fair to say that Moore’s Law has been kept alive considering the increase in the number of transistors per core, but having a slight drop in the rate. Don’t get me wrong or find me smug, but instead of saying that the law is dead, I’d rather say it may be dying.
This change increases the demand for languages that facilitate the development of applications that make good use of multiple cores, such as Go.
Contextualizing software needs
“Modern processors are a like nitro fueled funny cars, they excel at the quarter mile. Unfortunately modern programming languages are like Monte Carlo, they are full of twists and turns.” — David Ungar, OOPSLA
The Internet has brought a whole ocean of business opportunities, new business models and, with it, new types of information systems to meet these new demands. Today’s applications use multiple microservices to maintain database connections, message queues, and maintain caches.
Against the backdrop of the exponential increase in the number of transactions carried out through any Internet-enabled device, tens of billions being executed all the time — Visa does around 1,700 transactions per second on average (based on a calculation derived from the official claim of over 150 million transactions per day)— software systems become increasingly complex to meet new criteria and architectural drivers.
In order to support these new needs, have processing power, guarantee performance and in view of hardware limitations, other steps have been taken:
- Manufacturers began to add more and more cores to the processor. We currently have quad-core, octa-core, deca-core and dodeca-core CPUs available and so on;
- They also introduced hyper-threading;
- Manufacturers have added more processor cache to increase performance;
In the coming years this multi-core trend will absolutely continue.
On the other hand, these solutions cited above also have their own limitations. We cannot simply add more and more cache to the processor to increase performance because the cache has physical limits: the larger it is, the slower it gets. Adding more cores to the processor also comes at a cost and cannot scale indefinitely. These multi-core processors can run multiple threads simultaneously and this brings out the concurrency.
If we cannot blindly rely on hardware enhancements, a good alternative is to focus efforts on more efficient software to increase performance. However unfortunately, many modern programming languages are not as efficient and effective as that.
Concurrency is not parallelism
It is very common for people to refer to the idea of parallelism when they hear the word concurrency, a related but distinct concept. In computing, concurrency is the composition of independent execution processes, while parallelism is the simultaneous execution of (possibly related) processes.
Concurrency is about simultaneity, that is, dealing with many things at once. Parallelism is about doing many things at once.

To clarify this — possible — confusion, one of Go’s creators, Rob Pike, gave a talk at the Heroku’s Waza Conference entitled “Concurrency is not paralelism”:
How Go treats concurrency
As we discussed above, hardware manufacturers are adding more and more cores to processors to increase performance. The software we develop and the programming languages must — or at least should — easily withstand concurrency and scale with increasing cores.
However, most modern programming languages such as Java, Python and others have emerged in a very different and single-threaded 90s context.
Yes, most of these programming languages support multi-threading, but the real problem comes with concurrent execution, threading-locking, race conditions and deadlocks. This makes it very difficult to create multi-threading applications in this kind of language.
For example, creating a new thread in Java is not memory efficient at all. Each thread consumes approximately 1 MB of the memory heap size by default. Eventually if you start running thousands of threads, they will put a lot of pressure on the heap and may cause unexpected unavailability due to lack of memory. Also, if you want to communicate between two or more topics, it is very difficult.
On the other hand, Go came about when multi-core processors were already a very popular reality. In other words, the Go language has already been conceived with the idea of very solid and natural concurrency.
Goroutines instead of threads
Goroutines (execution)
Goroutine is lightweight execution thread running in the background. Goroutines are key ingredients to achieve concurrency in Go. It’s not a function or method definition that determines if were dealing with a goroutine, it is determined by how we invoke the routine.
Go provides a special keyword go to create a goroutine. When we call a function or a method with go prefix, that function or method executes in a goroutine. Let’s see a pretty simple example:

When we run this program, we see the output below of the blocking call first, then the interleaved output of the two goroutines. This interleaving reflects the goroutines being run concurrently by the Go runtime.

This is what happens behind the scenes:

Channels (communication)
Channels are pipes that connect concurrent goroutines. You can send values to channels in one goroutine and receive those values in another goroutine. This allows you to synchronize the execution.
You can create a new channel with make(chan val-type). Channels are typed by the values they convey.
You can send a value into a channel using the channel <- syntax. Here we send "ping" to the messages channel we made above, from a new goroutine.
The <-channel syntax receives a value from the channel. Here we’ll receive the "ping" message we sent above and print it out.
Let’s see an example:

When we run the program, the "ping" message is successfully passed from one goroutine to another via our channel. By default sends and receives block until both the sender and receiver are ready. This property allowed us to wait, at the end of our program, for the "ping" message without having to use any other synchronization.

Select (coordination)
Go select allows you to wait on multiple channels of operations. Combining goroutines and channels with select is a powerful feature of Go.
For our example we’ll select across two channels.
Each channel will receive a value after some amount of time, to simulate e.g. blocking RPC operations executing in concurrent goroutines.
We’ll use select to wait for both of these values, printing each one as it arrives. Let’s see an example:

We receive the values "one" and then "two" as expected.
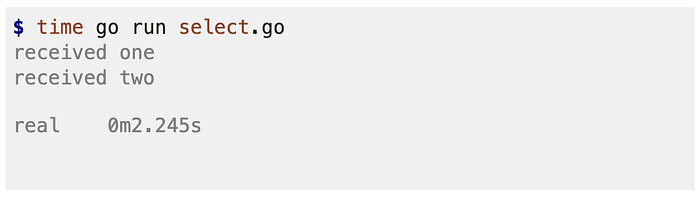
Note that the total execution time is only ~2 seconds since both the 1st and 2nd Sleeps execute concurrently.
Practical effects
Goroutines consume around 2 KB of heap memory. Then you can run millions of goroutines at any time.
Well, we’re talking about a 500% difference comparing with Java just in terms of memory allocation. This is huge. Of course you can change the default value for Java but you won’t be able to get even close to this efficiency.
In practice, in Java, you can run thousands or tens of thousands of threads. In Go you can run hundreds of thousands or millions of goroutines.
Java threads map directly to OS threads and are relatively heavy. Part of the reason why they are heavy is their rather large fixed stack size. This reduces the number of threads you can run on a single VM due to increased memory overhead.
Here are some other advantages of Goroutines on threads:
- Goroutines have segmented growing stacks. This means you can run more goroutines on a typical system than on threads, and they will use more memory only when needed;
- Goroutines have a faster boot time than threads;
- Goroutines come with built-in primitives to communicate securely with each other (channels);
- Goroutines allow you to avoid having to use mutex lock when sharing data structures;
- Goroutines and OS threads do not have 1:1 mapping. A single goroutine can run on multiple threads;
- Goroutines are multiplexed into a small number of operating system threads;
- You can massively write concurrent servers without having to resort to event scheduling.
Prevent locking hell
Golang offers native ways to avoid complete blocking. The mainstream is don’t communicate by sharing memory, share memory by communicating. In other words, if two goroutines need to share data, they can safely do so on one channel. Go takes care of all the syncing for you and it is much harder to come across deadlocks.
No callback spaghetti either
There are other approaches to achieving high concurrency with a small number of threads. Python Twisted was one of the first to receive notoriety. Node.js is currently quite prominent when we think of an event handling framework, for example.
The problem with these structures is that the complexity of the code is also high and difficult to maintain. Instead of the more direct and natural linear coding, the developer is forced to worry about how to keep everything synchronized and chain callbacks, which are interspersed with error handling. While refactoring can help tame part of the mental burden, it is still a problem.
In ECMAScript 6 we have ways to join promises and avoid some problems but it is still hard to build a good solution when we are talking about complex systems.
In Go, this is not necessary. Go handles all callback management natively and transparently.
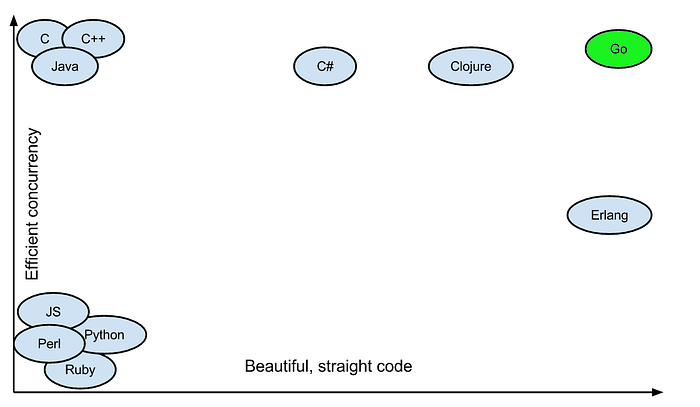
All of the above characteristics makes Go very powerful for dealing with concurrency like Java, C and C++, while keeping concurrency execution code as tight and beautiful as Erlang.
Go is directly compiled
For comparison, Java implementations use a two-step build process. Java source code is compiled in bytecode by the Java compiler and then executed by a JVM. Modern JVMs uses a technique called Just-in-Time (JIT) compilation to compile bytecode for native instructions understood by the hardware CPU at runtime.

Go is a compiled language. Even so it is compiled, it is portable. You can set the "GOOS" and "GOOARCH" environment variables before building:
GOOS=windows GOARCH=386 go build (or install or any other command)
By default, a binary will be built for the system you are running.
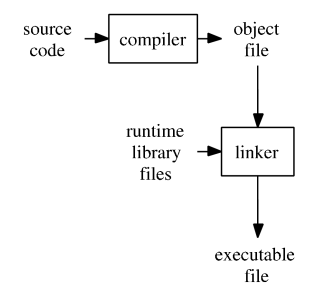
This means that we must execute our source files through a compiler, which reads the source code and generates a binary or executable file. Examples of other popular compiled languages include C, C ++, and Swift. Programs written in these languages are made into machine code and can run extremely fast.
Therefore, Go does not run on VMs and this removes steps from the run cycle and increases build performance. Go directly compiles source code for binaries:
Also, when we talk about compiled languages like C and C++, for example, allocating and releasing variables is a big pain. This is because all the work must be done programmatically and is often a major cause of memory leak as illustrated in this innocent and dangerous code written in C++:
int main() {
// OK
int * p = new int;
delete p;
// Memory leak
int * q = new int;
// no delete
}Go brings the best of both worlds. In addition to bringing performance close to low-level compiled languages like C / C ++, Go also completely abstracts memory management by implementing the low-latency Garbage Collector.
Just forget malloc() and free() statements :)
Benchmarks Game
We talked a little about concurrency, compilation and left the quote about performance open. Go can be seen to win most tests against other languages like Java, C # .Net Core and others. You can see the full results here.
However, what I would like to highlight is Go’s memory and CPU consumption compared to other languages. At these points, the advantage of Go is noticeable.
In practice, when we talk about cloud this is reflected in a drastic economy. If we think of IoT devices, this can also be crucial.
We can also see that Go is not silver bullet and even loses to other languages in some tests, especially today where languages in general have evolved a lot in terms of performance. There will always be a tradeoff.
Maintainability
Go has a very lean and clean syntax. Go was deliberately designed from the ground up to support large-scale programs implemented by hundreds or thousands of different people. These types of programs are written on Google, and Go is designed to be used to write programs there.
Some of the features of Go that are designed to serve large systems:
- No global namespace. The only name that needs to be unique in a Go package is its path in the file system. There is nothing like the C++ ODR rule, because name conflicts are impossible.
- No circular imports. If package A imports B, then package B will not be allowed to import package A, even indirectly. This forces programs to clearly specify dependencies.
- Boot order needs. As a consequence of the lack of circular imports, Go specifies that all imports from a package are initialized before the package itself is initialized. There is no risk of an initializer accidentally using an uninitialized value.
- Breadth First Search approach to search for field names against anonymous fields. If you embed another type of package anonymously, it cannot interfere with field name references, even if it adds another field with the same name.
- All build dependencies are expressed in the export data of a package. If package A imports B and imports C, then build A doesn’t need to look at C. This is different from C ++, where A often needs to include C’s header files. This speeds up the compilation of large programs.
Keep it simple
Go intentionally leaves out many features of modern OOP languages (even because it is structured).
- Classless. Everything is divided into packages only. Go has only structs instead of classes.
- Does not support inheritance. This will make the code easy to modify. In other languages like Java / Python, if class A inherits class B and you make some changes to class B, this can have some side effects on other classes that inherit B. By removing inheritance, Go makes it easier to understand code also, since there are no superclasses to read while using a certain part of subclass code.
- No constructors;
- No annotations;
- No generics;
- No exceptions;
This makes Go very different from other languages and makes Go programming also distinct. You may not like a few points above and there is no harm in that. On the plus side, this will make your code cleaner and add more clarity to it.
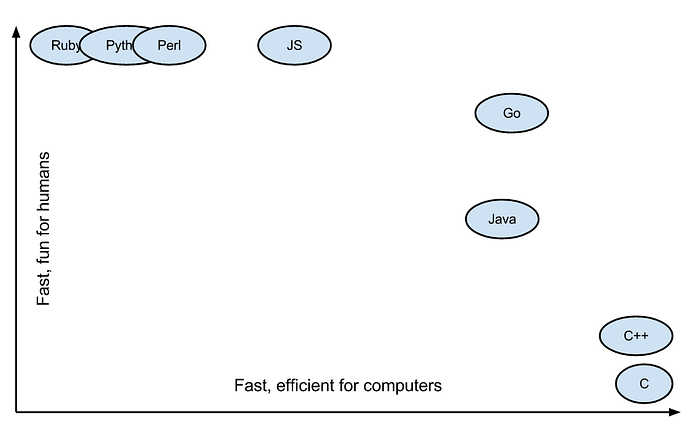
Go is almost as efficient as C / C ++, while maintaining the syntax of simple code like Ruby, Python, and other languages. This is a win-win situation for humans and processors.
Unlike other new languages like Swift, the syntax of Go is very stable. This makes it backwards compatible.
Built-in testing API
I think I don’t need to mention how important testing is for building good systems or even dwelling on practices like TDD, right?
Anyway, Go has a standard package namedtesting that provides support for automated testing of Go packages. It is intended to be used in concert with the “go test” command, which automates execution of any function of the form
func TestXxx(*testing.T)where Xxx does not start with a lowercase letter. The function name serves to identify the test routine. Within these functions, use the Error, Fail or related methods to signal failure.
To write a new test suite, create a file whose name ends in _test.go that contains the TestXxx functions as described here. Put the file in the same package as the one being tested. The file will be excluded from regular package builds but will be included when the “go test” command is run. You can also run “go help test” and “go help testflag” for more details.
A simple test function looks like this:
func TestAbs(t *testing.T) {
got := Abs(-1)
if got != 1 {
t.Errorf("Abs(-1) = %d; want 1", got)
}
}Backed by Google
Go is designed and maintained by Google. Google has one of the largest cloud infrastructures in the world and is massively scaled.
Golang was developed by Google to address your scalability and effectiveness to support issues. Depending on how big your operation is, these are the same issues you will face when creating your own servers.
In addition, Go is also used by some major companies like eBay, Adobe, Dell, GitHub, SpaceX, IBM, Intel, Booking.com. In Brazil, we can highlight 99Taxis, Dafiti, Globo.com and PagSeguro among others.
Final words
Golang’s popularity is growing at an increasing rate, and if you’re looking to develop cloud-native and serveless applications, for example, I think learning Go is a must.
With the advantages of build and run speed, your efficiency and execution cost are positively impacted, to say the least. It has become a critical component of cloud infrastructure and it is probably not going anywhere for some time.
Even though Go is very different from other object-oriented languages, it is still just a language, so why not learn it?
If you have no plans to learn Go, I still say that the hardware limit pushes us to write increasingly efficient code, not just the hardware but specially the current software context. Optimized software can run on cheaper, slower hardware such as IoT devices and generally has a better impact on the end user experience.
Revisor:
- Raul Costa, Software Engineer at European XFEL — Hamburg, Germany
References
- https://golang.org/
- http://goporexemplo.golangbr.org/
- https://blog.golang.org/concurrency-is-not-parallelism
- https://willowtreeapps.com/ideas/the-pros-and-cons-of-programming-in-go
- https://www.ft.com/content/11c1e372-e106-11e8-8e70-5e22a430c1ad
- https://www.extremetech.com/computing/256558-nvidias-ceo-declares-moores-law-dead
- https://www.technologyreview.com/s/601441/moores-law-is-dead-now-what/
- http://tleyden.github.io/blog/2014/10/30/goroutines-vs-threads
- https://medium.com/@kevalpatel2106/why-should-you-learn-go-f607681fad65
- https://devopedia.org/go-language
- http://www2.hawaii.edu/~takebaya/ics111/process_of_programming/process_of_programming.html
- https://hackernoon.com/golang-or-the-future-of-the-dev-984c2f145bbe
- https://medium.com/qash/golang-the-next-language-to-learn-for-developers-2c7c32b8a095
